반응형
5.2 머신러닝과 문서 분류 과정에 대한 이해
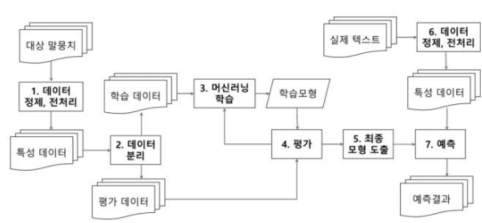
- 머신러닝을 이용한 문서 분류의 과정
- 데이터 정제, 전처리
- 데이터 분리
- 머신러닝 학습
- 평가
- 최종모형 도출
- 예측
5.3 나이브 베이즈 분류기를 이용한 문서 분류
- 사전 확률: 특성에 대한 정보가 없을 때 학습 데이터셋의 분포를 통해 확인한 확률
from sklearn.naive_bayes import MultinomialNB #sklearn이 제공하는 MultinomialNB 를 사용
NB_clf = MultinomialNB() # 분류기 선언
NB_clf.fit(X_train_cv, y_train) #train set을 이용하여 분류기(classifier)를 학습
print('Train set score: {:.3f}'.format(NB_clf.score(X_train_cv, y_train))) #train set에 대한 예측정확도를 확인
print('Test set score: {:.3f}'.format(NB_clf.score(X_test_cv, y_test))) #test set에 대한 예측정확도를 확인
"""
Train set score: 0.824
Test set score: 0.732
"""print('#First document and label in test data:', X_test[0], y_test[0])
print('#Second document and label in test data:', X_test[1], y_test[1])
pred = NB_clf.predict(X_test_cv[:2])
print('#Predicted labels:', pred)
print('#Predicted categories:', newsgroups_train.target_names[pred[0]], newsgroups_train.target_names[pred[1]])
"""
#First document and label in test data: TRry the SKywatch project in Arizona. 2
#Second document and label in test data: The Vatican library recently made a tour of the US.
Can anyone help me in finding a FTP site where this collection is
available. 1
#Predicted labels: [2 1]
#Predicted categories: sci.space comp.graphics
"""from sklearn.feature_extraction.text import TfidfVectorizer
#CountVectorizer와 동일한 인수를 사용
tfidf = TfidfVectorizer(max_features=2000, min_df=5, max_df=0.5)
X_train_tfidf = tfidf.fit_transform(X_train) # train set을 변환
X_test_tfidf = tfidf.transform(X_test) # test set을 변환
NB_clf.fit(X_train_tfidf, y_train) #tfidf train set을 이용하여 분류기(classifier)를 새로 학습
print('Train set score: {:.3f}'.format(NB_clf.score(X_train_tfidf, y_train))) #train set에 대한 예측정확도를 확인
print('Test set score: {:.3f}'.format(NB_clf.score(X_test_tfidf, y_test))) #test set에 대한 예측정확도를 확인
"""
Train set score: 0.862
Test set score: 0.741
"""import numpy as np
def top10_features(classifier, vectorizer, categories):
feature_names = np.asarray(vectorizer.get_feature_names_out())
for i, category in enumerate(categories):
# Retrieve the log probabilities of features for the current category
log_prob = classifier.feature_log_prob_[i]
# Sort the log probabilities in descending order and get the indices of the top 10
top10 = np.argsort(-log_prob)[:10]
# Retrieve the feature names corresponding to the indices
top_features = feature_names[top10]
# Print the category and top 10 features
print(f"{category}: {', '.join(top_features)}")
top10_features(NB_clf, tfidf, newsgroups_train.target_names)
"""
alt.atheism: you, not, are, be, this, have, as, what, they, if
comp.graphics: you, on, graphics, this, have, any, can, or, with, thanks
sci.space: space, on, you, be, was, this, as, they, have, are
talk.religion.misc: you, not, he, are, as, this, be, god, was, they
"""import numpy as np
def top10_features(classifier, vectorizer, categories):
feature_names = np.asarray(vectorizer.get_feature_names_out())
for i, category in enumerate(categories):
# 역순으로 정렬하기 위해 계수에 음수를 취해서 정렬 후 앞에서부터 10개의 값을 반환
top10 = np.argsort(-classifier.coef_[i])[:10]
# 카테고리와 영향이 큰 특성 10개를 출력
print("%s: %s" % (category, ", ".join(feature_names[top10])))
top10_features(NB_clf, tfidf, newsgroups_train.target_names)
"""
\nimport numpy as np\n\ndef top10_features(classifier, vectorizer, categories):\n feature_names = np.asarray(vectorizer.get_feature_names_out())\n for i, category in enumerate(categories):\n # 역순으로 정렬하기 위해 계수에 음수를 취해서 정렬 후 앞에서부터 10개의 값을 반환\n top10 = np.argsort(-classifier.coef_[i])[:10]\n # 카테고리와 영향이 큰 특성 10개를 출력\n print("%s: %s" % (category, ", ".join(feature_names[top10])))\n\ntop10_features(NB_clf, tfidf, newsgroups_train.target_names)\n
"""
※ 해당 내용은 <파이썬 텍스트 마이닝 완벽 가이드>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'텍스트 마이닝' 카테고리의 다른 글
| BOW 기반의 문서 분류 (4) (0) | 2023.07.03 |
|---|---|
| BOW 기반의 문서 분류 (3) (0) | 2023.07.02 |
| BOW 기반의 문서 분류 (1) (0) | 2023.06.30 |
| 카운트 기반의 문서 표현 (5) (0) | 2023.06.29 |
| 카운트 기반의 문서 표현 (4) (0) | 2023.06.28 |

