8-1 합성곱(Convolution) 연산
- 합성곱 이해하기

- 합성곱 구현하기
1. 넘파이 배열 정의하고 배열 하나 선택해 뒤집기
import numpy as np
w = np.array([2, 1, 5, 3])
x = np.array([2, 8, 3, 7, 1, 2, 0, 4, 5])
w_r = np.flip(w)
print(w_r)
##출력: [3 5 1 2]
2. 넘파이의 점 곱으로 합성곱 수행하기
for i in range(6):
print(np.dot(x[i:i+4], w_r))
##출력:
63
48
49
28
21
20
3. 싸이파이로 합성곱 수행하기
from scipy.signal import convolve
convolve(x, w, mode='valid')
##출력: array([63, 48, 49, 28, 21, 20])
- 교차 상관
대부분의 딥러닝 패키지들은 합성곱 신경망을 만들 때 교차 상관을 사용
교차 상관은 합성곱과 동일한 방법으로 연산이 진행되지만 '미끄러지는 배열을 뒤집지 않음'
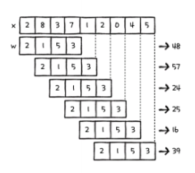
from scipy.signal import correlate
correlate(x, w, mode='valid')
##출력: array([48, 57, 24, 25, 16, 39])
- 합성곱 신경망에서 교차 상관을 사용하는 이유

모든 모델은 훈련하기 전 가중치 배열의 요소들을 무작위로 초기화하기에 가중치인 '미끄러지는 배열'이 뒤집어져 있는지 여부가 중요하지 않음
- 패딩과 스트라이드
패딩(padding) : 원본 배열의 양 끝에 빈 원소를 추가하는 것 -> 합성곱 신경망에서는 대부분 세임 패딩을 사용
스트라이드(stride) : 미끄러지는 배열의 간격을 조절한 것
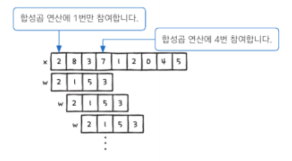
- 벨리드 패딩(Valid padding)
원본 배열의 원소가 합성곱 연산에 참여하는 정도가 서로 다름
mode 매개변수에 'valid'를 지정한 것
벨리드 패딩의 결과로 얻는 배열의 크기는 원본 배열보다 항상 작음
- 풀 패딩(Full padding)
원본 배열의 모든 요소가 동일하게 연산에 참여하는 패딩 방식
원본 배열의 양 끈테 가상의 원소를 추가하는 제로 패딩(Zero padding)이 필요

correlate(x, w, mode='full')
##출력: array([ 6, 34, 51, 48, 57, 24, 25, 16, 39, 29, 13, 10])
- 세임 패딩(Same padding)
출력 배열의 길이를 원본 배열의 길이와 동일하게 만든 것
출력 배열의 길이가 원본 배열의 길이와 같이지도록 원본 배열에 제로 패딩 추가

correlate(x, w, mode='same')
##출력: array([34, 51, 48, 57, 24, 25, 16, 39, 29])- 스트라이드(stride)
미끄러지는 배열의 간격
미끄러지는 간격을 조정
합성곱 신경망을 만들 때는 보통 스트라이드를 1로 지정

※ 해당 내용은 <Do it! 딥러닝 입문>의 내용을 토대로 학습하며 정리한 내용입니다.
'딥러닝 학습' 카테고리의 다른 글
| 8장 이미지 분류 - 합성곱 신경망 (3) (0) | 2023.03.18 |
|---|---|
| 8장 이미지 분류 - 합성곱 신경망 (2) (0) | 2023.03.17 |
| 7장 여러개를 분류 - 다중 분류 (3) (0) | 2023.03.15 |
| 7장 여러개를 분류 - 다중 분류 (2) (0) | 2023.03.14 |
| 7장 여러개를 분류 - 다중 분류 (1) (0) | 2023.03.13 |



