반응형
7-1 여러 개의 이미지를 분류하는 다층 신경망
다층 신경망을 만들기 위해 소프트맥스(softmax) 함수, 크로스 엔트로피(cross-entropy) 손실 함수를 알아야함
- 다중 분류 신경망

- 다중 분류의 문제점과 소프트맥스 함수
활성화 출력의 합이 1이 아니면 비교하기 어려움
소프트맥스 함수 적용하여 출력 강도 정규화
소프트맥스 함수 : 출력층의 출력 강도를 정규화(전체 출력값의 합을 1로 만듬)

- 크로스 엔트로피 손실 함수의 도입

- 크로스 엔트로피 손실 함수 미분
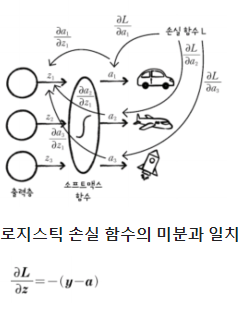
- 다중 분류 신경망 구현
1. 소프트맥스 함수 추가
def sigmoid(self, z):
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
a = 1 / (1 + np.exp(-z)) # 시그모이드 계산
return a
def softmax(self, z):
# 소프트맥스 함수
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
exp_z = np.exp(z)
return exp_z / np.sum(exp_z, axis=1).reshape(-1, 1)
2. 정방향 계산
def forpass(self, x):
z1 = np.dot(x, self.w1) + self.b1 # 첫 번째 층의 선형 식을 계산합니다
self.a1 = self.sigmoid(z1) # 활성화 함수를 적용합니다
z2 = np.dot(self.a1, self.w2) + self.b2 # 두 번째 층의 선형 식을 계산합니다.
return z2
3. 가중치 초기화
def init_weights(self, n_features, n_classes):
self.w1 = np.random.normal(0, 1, (n_features, self.units)) # (특성 개수, 은닉층의 크기)
self.b1 = np.zeros(self.units) # 은닉층의 크기
self.w2 = np.random.normal(0, 1, (self.units, n_classes)) # (은닉층의 크기, 클래스 개수)
self.b2 = np.zeros(n_classes)
4. fit() 메서드 수정
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
np.random.seed(42)
self.init_weights(x.shape[1], y.shape[1]) # 은닉층과 출력층의 가중치를 초기화합니다.
# epochs만큼 반복합니다.
for i in range(epochs):
loss = 0
print('.', end='')
# 제너레이터 함수에서 반환한 미니배치를 순환합니다.
for x_batch, y_batch in self.gen_batch(x, y):
a = self.training(x_batch, y_batch)
# 안전한 로그 계산을 위해 클리핑합니다.
a = np.clip(a, 1e-10, 1-1e-10)
# 로그 손실과 규제 손실을 더하여 리스트에 추가합니다.
loss += np.sum(-y_batch*np.log(a))
self.losses.append((loss + self.reg_loss()) / len(x))
# 검증 세트에 대한 손실을 계산합니다.
self.update_val_loss(x_val, y_val)
5. training() 메서드 수정
def training(self, x, y):
m = len(x) # 샘플 개수를 저장합니다.
z = self.forpass(x) # 정방향 계산을 수행합니다.
a = self.softmax(z) # 활성화 함수를 적용합니다.
err = -(y - a) # 오차를 계산합니다.
# 오차를 역전파하여 그래디언트를 계산합니다.
w1_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
# 그래디언트에서 페널티 항의 미분 값을 뺍니다
w1_grad += (self.l1 * np.sign(self.w1) + self.l2 * self.w1) / m
w2_grad += (self.l1 * np.sign(self.w2) + self.l2 * self.w2) / m
# 은닉층의 가중치와 절편을 업데이트합니다.
self.w1 -= self.lr * w1_grad
self.b1 -= self.lr * b1_grad
# 출력층의 가중치와 절편을 업데이트합니다.
self.w2 -= self.lr * w2_grad
self.b2 -= self.lr * b2_grad
return a
6. predict() 메서드 수정
def predict(self, x):
z = self.forpass(x) # 정방향 계산을 수행합니다.
return np.argmax(z, axis=1) # 가장 큰 값의 인덱스를 반환합니다.
7. score() 메서드 수정
def score(self, x, y):
# 예측과 타깃 열 벡터를 비교하여 True의 비율을 반환합니다.
return np.mean(self.predict(x) == np.argmax(y, axis=1))
8. 검증 손실 계산
def update_val_loss(self, x_val, y_val):
z = self.forpass(x_val) # 정방향 계산을 수행합니다.
a = self.softmax(z) # 활성화 함수를 적용합니다.
a = np.clip(a, 1e-10, 1-1e-10) # 출력 값을 클리핑합니다.
# 크로스 엔트로피 손실과 규제 손실을 더하여 리스트에 추가합니다.
val_loss = np.sum(-y_val*np.log(a))
self.val_losses.append((val_loss + self.reg_loss()) / len(y_val))반응형
※ MultiClassNetwork 클래스 코드
class MultiClassNetwork:
def __init__(self, units=10, batch_size=32, learning_rate=0.1, l1=0, l2=0):
self.units = units # 은닉층의 뉴런 개수
self.batch_size = batch_size # 배치 크기
self.w1 = None # 은닉층의 가중치
self.b1 = None # 은닉층의 절편
self.w2 = None # 출력층의 가중치
self.b2 = None # 출력층의 절편
self.a1 = None # 은닉층의 활성화 출력
self.losses = [] # 훈련 손실
self.val_losses = [] # 검증 손실
self.lr = learning_rate # 학습률
self.l1 = l1 # L1 손실 하이퍼파라미터
self.l2 = l2 # L2 손실 하이퍼파라미터
def forpass(self, x):
z1 = np.dot(x, self.w1) + self.b1 # 첫 번째 층의 선형 식을 계산합니다
self.a1 = self.sigmoid(z1) # 활성화 함수를 적용합니다
z2 = np.dot(self.a1, self.w2) + self.b2 # 두 번째 층의 선형 식을 계산합니다.
return z2
def backprop(self, x, err):
m = len(x) # 샘플 개수
# 출력층의 가중치와 절편에 대한 그래디언트를 계산합니다.
w2_grad = np.dot(self.a1.T, err) / m
b2_grad = np.sum(err) / m
# 시그모이드 함수까지 그래디언트를 계산합니다.
err_to_hidden = np.dot(err, self.w2.T) * self.a1 * (1 - self.a1)
# 은닉층의 가중치와 절편에 대한 그래디언트를 계산합니다.
w1_grad = np.dot(x.T, err_to_hidden) / m
b1_grad = np.sum(err_to_hidden, axis=0) / m
return w1_grad, b1_grad, w2_grad, b2_grad
def sigmoid(self, z):
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
a = 1 / (1 + np.exp(-z)) # 시그모이드 계산
return a
def softmax(self, z):
# 소프트맥스 함수
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
exp_z = np.exp(z)
return exp_z / np.sum(exp_z, axis=1).reshape(-1, 1)
def init_weights(self, n_features, n_classes):
self.w1 = np.random.normal(0, 1, (n_features, self.units)) # (특성 개수, 은닉층의 크기)
self.b1 = np.zeros(self.units) # 은닉층의 크기
self.w2 = np.random.normal(0, 1, (self.units, n_classes)) # (은닉층의 크기, 클래스 개수)
self.b2 = np.zeros(n_classes)
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
np.random.seed(42)
self.init_weights(x.shape[1], y.shape[1]) # 은닉층과 출력층의 가중치를 초기화합니다.
# epochs만큼 반복합니다.
for i in range(epochs):
loss = 0
print('.', end='')
# 제너레이터 함수에서 반환한 미니배치를 순환합니다.
for x_batch, y_batch in self.gen_batch(x, y):
a = self.training(x_batch, y_batch)
# 안전한 로그 계산을 위해 클리핑합니다.
a = np.clip(a, 1e-10, 1-1e-10)
# 로그 손실과 규제 손실을 더하여 리스트에 추가합니다.
loss += np.sum(-y_batch*np.log(a))
self.losses.append((loss + self.reg_loss()) / len(x))
# 검증 세트에 대한 손실을 계산합니다.
self.update_val_loss(x_val, y_val)
# 미니배치 제너레이터 함수
def gen_batch(self, x, y):
length = len(x)
bins = length // self.batch_size # 미니배치 횟수
if length % self.batch_size:
bins += 1 # 나누어 떨어지지 않을 때
indexes = np.random.permutation(np.arange(len(x))) # 인덱스를 섞습니다.
x = x[indexes]
y = y[indexes]
for i in range(bins):
start = self.batch_size * i
end = self.batch_size * (i + 1)
yield x[start:end], y[start:end] # batch_size만큼 슬라이싱하여 반환합니다.
def training(self, x, y):
m = len(x) # 샘플 개수를 저장합니다.
z = self.forpass(x) # 정방향 계산을 수행합니다.
a = self.softmax(z) # 활성화 함수를 적용합니다.
err = -(y - a) # 오차를 계산합니다.
# 오차를 역전파하여 그래디언트를 계산합니다.
w1_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
# 그래디언트에서 페널티 항의 미분 값을 뺍니다
w1_grad += (self.l1 * np.sign(self.w1) + self.l2 * self.w1) / m
w2_grad += (self.l1 * np.sign(self.w2) + self.l2 * self.w2) / m
# 은닉층의 가중치와 절편을 업데이트합니다.
self.w1 -= self.lr * w1_grad
self.b1 -= self.lr * b1_grad
# 출력층의 가중치와 절편을 업데이트합니다.
self.w2 -= self.lr * w2_grad
self.b2 -= self.lr * b2_grad
return a
def predict(self, x):
z = self.forpass(x) # 정방향 계산을 수행합니다.
return np.argmax(z, axis=1) # 가장 큰 값의 인덱스를 반환합니다.
def score(self, x, y):
# 예측과 타깃 열 벡터를 비교하여 True의 비율을 반환합니다.
return np.mean(self.predict(x) == np.argmax(y, axis=1))
def reg_loss(self):
# 은닉층과 출력층의 가중치에 규제를 적용합니다.
return self.l1 * (np.sum(np.abs(self.w1)) + np.sum(np.abs(self.w2))) + \
self.l2 / 2 * (np.sum(self.w1**2) + np.sum(self.w2**2))
def update_val_loss(self, x_val, y_val):
z = self.forpass(x_val) # 정방향 계산을 수행합니다.
a = self.softmax(z) # 활성화 함수를 적용합니다.
a = np.clip(a, 1e-10, 1-1e-10) # 출력 값을 클리핑합니다.
# 크로스 엔트로피 손실과 규제 손실을 더하여 리스트에 추가합니다.
val_loss = np.sum(-y_val*np.log(a))
self.val_losses.append((val_loss + self.reg_loss()) / len(y_val))
※ 해당 내용은 <Do it! 딥러닝 입문>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'딥러닝 학습' 카테고리의 다른 글
| 7장 여러개를 분류 - 다중 분류 (3) (0) | 2023.03.15 |
|---|---|
| 7장 여러개를 분류 - 다중 분류 (2) (0) | 2023.03.14 |
| 6장 2개의 층을 연결 - 다층 신경망 (4) (0) | 2023.03.12 |
| 6장 2개의 층을 연결 - 다층 신경망 (3) (0) | 2023.03.11 |
| 6장 2개의 층을 연결 - 다층 신경망 (2) (0) | 2023.03.10 |



