반응형
2.4 품사 태깅
2.4.1 품사의 이해
- 품사: 명사, 대명사, 수사, 조사, 동사, 형용사, 관형사, 부사, 감탄사와 같이 공통된 성질을 지닌 낱말끼리 모아 놓은 낱말의 갈래


공용 품사 태그 집합


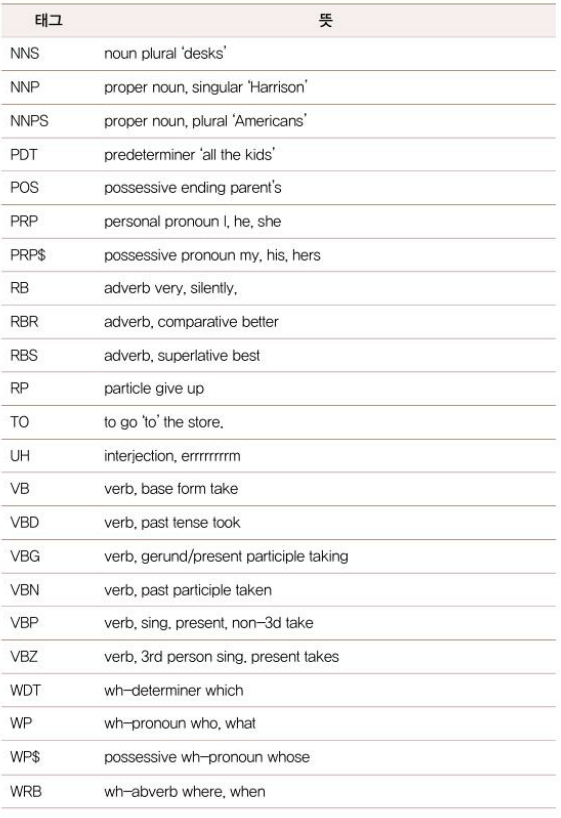
펜 트리뱅크 태그 집합

2.4.2 NLTK를 활용한 품사 태킹
import nltk
from nltk.tokenize import word_tokenize
tokens = word_tokenize("Hello everyone. It's good to see you. Let's start our text mining class!")
print(nltk.pos_tag(tokens))
## [('Hello', 'NNP'), ('everyone', 'NN'), ('.', '.'), ('It', 'PRP'), ("'s", 'VBZ'), ('good', 'JJ'), ('to', 'TO'), ('see', 'VB'), ('you', 'PRP'), ('.', '.'), ('Let', 'VB'), ("'s", 'POS'), ('start', 'VB'), ('our', 'PRP$'), ('text', 'NN'), ('mining', 'NN'), ('class', 'NN'), ('!', '.')]# 펜 트리뱅크 태그 집합 사용
#nltk.help.upenn_tagset('CC')
"""
CC: conjunction, coordinating
& 'n and both but either et for less minus neither nor or plus so
therefore times v. versus vs. whether yet
"""
"""
\nCC: conjunction, coordinating\n & 'n and both but either et for less minus neither nor or plus so\n therefore times v. versus vs. whether yet\n
"""- 원하는 품사의 단어들만 추출
my_tag_set = ['NN', 'VB', 'JJ']
my_words = [word for word, tag in nltk.pos_tag(tokens) if tag in my_tag_set]
print(my_words)
## ['everyone', 'good', 'see', 'Let', 'start', 'text', 'mining', 'class']- 단어에 품사 정보를 추가해 구분
words_with_tag = ['/'.join(item) for item in nltk.pos_tag(tokens)]
print(words_with_tag)
## ['Hello/NNP', 'everyone/NN', './.', 'It/PRP', "'s/VBZ", 'good/JJ', 'to/TO', 'see/VB', 'you/PRP', './.', 'Let/VB', "'s/POS", 'start/VB', 'our/PRP$', 'text/NN', 'mining/NN', 'class/NN', '!/.']2.4.3 한글 형태소 분석과 품사 태킹
- 형태소 분석
- 형태소: 뜻을 가진 가장 작은 말의 단위
- 음절: 하나의 종합된 음의 느낌을 주는 말소리의 단위
- 음절의 다음 단위가 형태소
- 문장의 의미를 알아야 하기 때문에 단어 단위가 아닌 형태소 단위로 토큰화 진행
- 품사 태깅
- 영어에는 직접적으로 조사가 없고, 이와 비슷한 기능을 하는 전치사와 be동사가 있을 수 있으나 분명한 차이가 있음
- 영어는 명사, 대명사, 형용사, 동사, 부사, 전치사, 접속사, 감탄사의 8 품사
- 한글은 전치사와 접속사가 없고, 수사, 조사, 관형사가 들어간 9 품사
- 한글 형태소 분석과 품사 태깅
sentence = '''절망의 반대가 희망은 아니다.
어두운 밤하늘에 별이 빛나듯
희망은 절망 속에 싹트는 거지
만약에 우리가 희망함이 적다면
그 누가 세상을 비출어줄까.
정희성, 희망 공부'''
tokens = word_tokenize(sentence)
print(tokens)
print(nltk.pos_tag(tokens))
"""
['절망의', '반대가', '희망은', '아니다', '.', '어두운', '밤하늘에', '별이', '빛나듯', '희망은', '절망', '속에', '싹트는', '거지', '만약에', '우리가', '희망함이', '적다면', '그', '누가', '세상을', '비출어줄까', '.', '정희성', ',', '희망', '공부']
[('절망의', 'JJ'), ('반대가', 'NNP'), ('희망은', 'NNP'), ('아니다', 'NNP'), ('.', '.'), ('어두운', 'VB'), ('밤하늘에', 'JJ'), ('별이', 'NNP'), ('빛나듯', 'NNP'), ('희망은', 'NNP'), ('절망', 'NNP'), ('속에', 'NNP'), ('싹트는', 'NNP'), ('거지', 'NNP'), ('만약에', 'NNP'), ('우리가', 'NNP'), ('희망함이', 'NNP'), ('적다면', 'NNP'), ('그', 'NNP'), ('누가', 'NNP'), ('세상을', 'NNP'), ('비출어줄까', 'NNP'), ('.', '.'), ('정희성', 'NN'), (',', ','), ('희망', 'NNP'), ('공부', 'NNP')]
"""- KoNLPy의 형태소 분석 및 품사 태깅 기능 사용법
print('형태소:', t.morphs(sentence))
print()
print('명사:', t.nouns(sentence))
print()
print('품사 태깅 결과:', t.pos(sentence))
"""
형태소: ['절망', '의', '반대', '가', '희망', '은', '아니다', '.', '\n', '어', '두운', '밤하늘', '에', '별', '이', '빛나듯', '\n', '희망', '은', '절망', '속', '에', '싹트는', '거지', '\n', '만약', '에', '우리', '가', '희망', '함', '이', '적다면', '\n', '그', '누가', '세상', '을', '비출어줄까', '.', '\n', '정희성', ',', '희망', '공부']
명사: ['절망', '반대', '희망', '어', '두운', '밤하늘', '별', '희망', '절망', '속', '거지', '만약', '우리', '희망', '함', '그', '누가', '세상', '정희성', '희망', '공부']
품사 태깅 결과: [('절망', 'Noun'), ('의', 'Josa'), ('반대', 'Noun'), ('가', 'Josa'), ('희망', 'Noun'), ('은', 'Josa'), ('아니다', 'Adjective'), ('.', 'Punctuation'), ('\n', 'Foreign'), ('어', 'Noun'), ('두운', 'Noun'), ('밤하늘', 'Noun'), ('에', 'Josa'), ('별', 'Noun'), ('이', 'Josa'), ('빛나듯', 'Verb'), ('\n', 'Foreign'), ('희망', 'Noun'), ('은', 'Josa'), ('절망', 'Noun'), ('속', 'Noun'), ('에', 'Josa'), ('싹트는', 'Verb'), ('거지', 'Noun'), ('\n', 'Foreign'), ('만약', 'Noun'), ('에', 'Josa'), ('우리', 'Noun'), ('가', 'Josa'), ('희망', 'Noun'), ('함', 'Noun'), ('이', 'Josa'), ('적다면', 'Verb'), ('\n', 'Foreign'), ('그', 'Noun'), ('누가', 'Noun'), ('세상', 'Noun'), ('을', 'Josa'), ('비출어줄까', 'Verb'), ('.', 'Punctuation'), ('\n', 'Foreign'), ('정희성', 'Noun'), (',', 'Punctuation'), ('희망', 'Noun'), ('공부', 'Noun')]
"""
※ 해당 내용은 <파이썬 텍스트 마이닝 완벽 가이드>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'텍스트 마이닝' 카테고리의 다른 글
| 그래프와 워드 클라우드 (2) (0) | 2023.06.23 |
|---|---|
| 그래프와 워드 클라우드 (1) (0) | 2023.06.22 |
| 텍스트 전처리 (3) (0) | 2023.06.20 |
| 텍스트 전처리 (2) (0) | 2023.06.19 |
| 텍스트 전처리 (1) (0) | 2023.06.18 |

