반응형
7-5 기본 모델
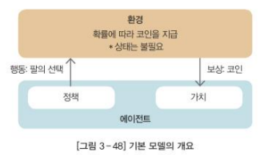
- 가장 간단한 형태로 모델에 상태나 정책이 없고, 주어진 확률에 따라 행동하며 그에 따라 보상이 지급
탐욕 알고리즘(Greedy Algorithm)
- 현단계에서 최선은 아니지만, 전체적으로 최선인 경로를 선택하기 위해 개발된 것
UCB1 알고리즘(Upper Confidence Bound1 Algorithm)
- '성공률' + '바이어스'를 최대로 만드는 행동을 선택하는 방법
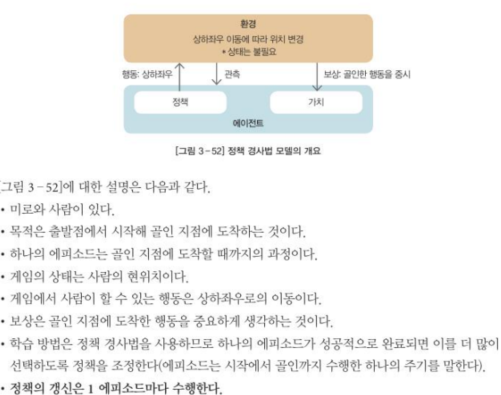
7-6 정책 경사법 모델
- 주어진 환경에서 상태를 갖고 관측하는 기능을 추가
- 강화학습에서 사용하는 가장 일반적인 모델 유형
정책 경사법의 학습 순서
- 1) 초기 정책을 준비
- 2) 정책을 파라미터로 변환
- 3) 파라미터에 따라 골인 지점에 이를 때까지 행동을 반복
- 4) 성공한 경우, 성공한 행동을 많이 받아들이도록 파라미터를 변경
- 5) 파라미터 변화량이 임곗값 이하가 될 때까지 3),4) 과정 반복
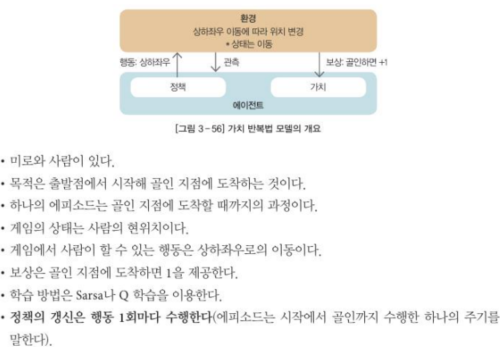
7-7 가치 반복법 모델
- 어떤 행동을 선택할 때 다음 상태 가치와 현상태 가치의 차이를 계산하고, 그 차이만큼 현상태의 가치를 증가시키는 방법
행동 가치 함수(Action Value Function)
- 특정한 상태에서 특정한 행동을 선택하는 가치를 계산하는 함수
- Q 함수
상태 가치 함수(State Value Function)
- 특정 상태의 가치를 계산하는 함수
벨만 방정식(Bellman Equation)
- 행동 가치 함수와 상태 가치 함수를 일반적인 형태로 서술한 것
- 벨만방정식으로부터 행동 가치 함수를 학습하는 방법: Sarsa, Q

7-8 DQN(Deep Q Networks)
- 가치 반복법과 딥러닝을 합친 것
- 반복되는 학습 과정이 Q 테이블을 최적화시키는 것과 같은 역할을 함

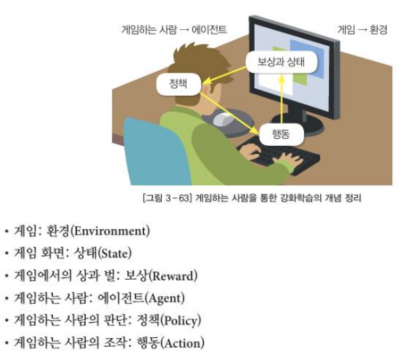
7-9 강화학습의 예
※ 해당 내용은 <인공지능 바이블>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'인공지능(AI)' 카테고리의 다른 글
| 딥러닝 (2) (0) | 2023.05.30 |
|---|---|
| 딥러닝 (1) (0) | 2023.05.29 |
| 강화 학습 (1) (0) | 2023.05.27 |
| 통계 기반 기계 학습 - 비지도 학습 (0) | 2023.05.26 |
| 통계 기반 기계 학습 - 지도학습 (0) | 2023.05.25 |



