반응형
9-2 순환 신경망 만들고 텍스트 분류
- 훈련 세트와 검증 세트 준비
IMDB 데이터 세트(인터넷 영화 데이터베이스(Internet Movie Database)에서 수집한 영화 리뷰 데이터)
훈련 세트 25,000개, 테스트 세트 25,000개
(훈련 세트에서 5,000개 분리하여 검증 세트로 사용)
1. 텐서플로에서 IMDB 데이터 세트 불러오기
import numpy as np
from tensorflow.keras.datasets import imdb
(x_train_all, y_train_all), (x_test, y_test) = imdb.load_data(skip_top=20, num_words=100)
##출력
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 [==============================] - 0s 0us/step
2. 훈련 세트 크기 확인
print(x_train_all.shape, y_train_all.shape)
##출력: (25000,) (25000,)
3. 훈련 세트의 샘플 확인
print(x_train_all[0])
##출력: [2, 2, 22, 2, 43, 2, 2, 2, 2, 65, 2, 2, 66, 2, 2, 2, 36, 2, 2, 25, 2, 43, 2, 2, 50, 2, 2, 2, 35, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 39, 2, 2, 2, 2, 2, 2, 38, 2, 2, 2, 2, 50, 2, 2, 2, 2, 2, 2, 22, 2, 2, 2, 2, 2, 22, 71, 87, 2, 2, 43, 2, 38, 76, 2, 2, 2, 2, 22, 2, 2, 2, 2, 2, 2, 2, 2, 2, 62, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 66, 2, 33, 2, 2, 2, 2, 38, 2, 2, 25, 2, 51, 36, 2, 48, 25, 2, 33, 2, 22, 2, 2, 28, 77, 52, 2, 2, 2, 2, 82, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 36, 71, 43, 2, 2, 26, 2, 2, 46, 2, 2, 2, 2, 2, 2, 88, 2, 2, 2, 2, 98, 32, 2, 56, 26, 2, 2, 2, 2, 2, 2, 2, 22, 21, 2, 2, 26, 2, 2, 2, 30, 2, 2, 51, 36, 28, 2, 92, 25, 2, 2, 2, 65, 2, 38, 2, 88, 2, 2, 2, 2, 2, 2, 2, 2, 32, 2, 2, 2, 2, 2, 32]
4. 훈련 세트에서 2 제외
for i in range(len(x_train_all)):
x_train_all[i] = [w for w in x_train_all[i] if w > 2]
print(x_train_all[0])
##출력: [22, 43, 65, 66, 36, 25, 43, 50, 35, 39, 38, 50, 22, 22, 71, 87, 43, 38, 76, 22, 62, 66, 33, 38, 25, 51, 36, 48, 25, 33, 22, 28, 77, 52, 82, 36, 71, 43, 26, 46, 88, 98, 32, 56, 26, 22, 21, 26, 30, 51, 36, 28, 92, 25, 65, 38, 88, 32, 32]
5. 어휘 사전 내려받기
word_to_index = imdb.get_word_index()
word_to_index['movie']
##출력
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json
1641221/1641221 [==============================] - 0s 0us/step
17
6. 훈련 세트의 정수를 영단어로 변환
index_to_word = {word_to_index[k]: k for k in word_to_index}
for w in x_train_all[0]:
print(index_to_word[w - 3], end=' ')
##출력: film just story really they you just there an from so there film film were great just so much film would really at so you what they if you at film have been good also they were just are out because them all up are film but are be what they have don't you story so because all all
7. 훈련 샘플의 길이 확인
print(len(x_train_all[0]), len(x_train_all[1]))
##출력: 59 32
8. 훈련 세트의 타깃 데이터 확인
print(y_train_all[:10])
##출력: [1 0 0 1 0 0 1 0 1 0]
9. 검증 세트 준비
np.random.seed(42)
random_index = np.random.permutation(25000)
x_train = x_train_all[random_index[:20000]]
y_train = y_train_all[random_index[:20000]]
x_val = x_train_all[random_index[20000:]]
y_val = y_train_all[random_index[20000:]]
반응형
- 샘플 길이 맞추기
일정 길이가 넘으면 자르고, 길이가 모자라면 0으로 채움
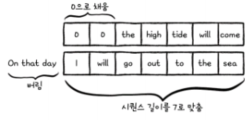
1. 텐서플로로 샘플의 길이 맞추기
from tensorflow.keras.preprocessing import sequence
maxlen=100
x_train_seq = sequence.pad_sequences(x_train, maxlen=maxlen)
x_val_seq = sequence.pad_sequences(x_val, maxlen=maxlen)
2. 길이를 조정한 훈련 세트의 크기와 샘플 확인
print(x_train_seq.shape, x_val_seq.shape)
print(x_train_seq[0])
##출력
(20000, 100) (5000, 100)
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 35 40 27 28 40 22 83 31 85 45
24 23 31 70 31 76 30 98 32 22 28 51 75 56 30 33 97 53 38 46 53 74 31 35
23 34 22 58]- 샘플 원-핫 인코딩하기
1. 텐서플로로 원-핫 인코딩하기
from tensorflow.keras.utils import to_categorical
x_train_onehot = to_categorical(x_train_seq)
x_val_onehot = to_categorical(x_val_seq)
2. 원-핫 인코딩으로 변환된 변수 x_train_onehot의 크기 확인
print(x_train_onehot.shape)
##출력: (20000, 100, 100)
3. x_train_onehot 크기 확인하면 760MB에 다다름
print(x_train_onehot.nbytes)
##출력: 800000000
훈련에 사용할 단어의 개수가 늘어나면 컴퓨터의 메모리가 더 필요
※ 해당 내용은 <Do it! 딥러닝 입문>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'딥러닝 학습' 카테고리의 다른 글
| 9장 텍스트 분류 - 순환신경망 (4) (0) | 2023.03.24 |
|---|---|
| 9장 텍스트 분류 - 순환신경망 (3) (0) | 2023.03.23 |
| 9장 텍스트 분류 - 순환신경망 (1) (0) | 2023.03.21 |
| 8장 이미지 분류 - 합성곱 신경망 (5) (0) | 2023.03.20 |
| 8장 이미지 분류 - 합성곱 신경망 (4) (0) | 2023.03.19 |



